More Details for Data Buffs
I ran a script on all Appalachian Trail hiker journals from 2001-2016 to gather each entry's starting location and journal entry date ("Start Location" was used rather than "Destination" since there was no guarantee that the hiker would actually reach their desired destination that day).
There were 325,000 entries in total, with 234,000 having usable data in the Start Location field. The rest either were either blank, contained non-AT locations (such as "home"), vague locations (such as "stealth camp" or "in the woods"), or locations that were otherwise unidentifiable.
All 234,000 entries were manually examined and standardized to one of 910 known locations along the trail. While some automation was used to identify large batches of locations, manual examination was necessary to identify entries with misspellings, alternate spellings, or outdated names.
Also, as thru-hikers will doubtless know, multiple locations along the trail share the same name (e.g., there are two shelters named Cove Mountain, two towns named Waynesboro, and five(!) Deep Gaps). Differentiating these was done by using the "Destination" field to determine which geographic area the hiker was in at the time.
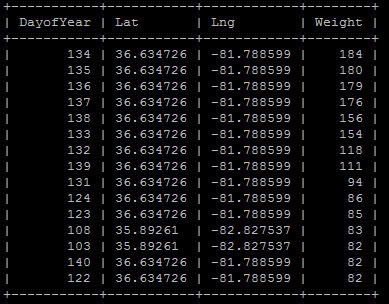
The data is stored in a MySQL database, and the visualizatons are generated using the Chart.js library and Vue.js framework. Below is an example of how the data is structured in the database. "Weight" represents the number of hikers found a set of coordinates on that particular day of the year.